3-1 数据库架构
关系型数据库考点思维导图
如何设计一个关系型数据库
3-2 索引模块
常见问题
- 为什么要使用索引
- 索引能避免全表扫描,快速查询数据,提升检索效率
- 什么样的信息能成为索引
- 主键、唯一键以及普通键等能让数据有一定区分性的数据
- 索引的数据结构
- 密集索引和稀疏索引的区别
3-2-1 优化你的索引-运用二叉查找树
- 若左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 若右子树不空,则右子树上所有结点的值均大于它的根结点的值;
3-2-2 优化你的索引-运用B树
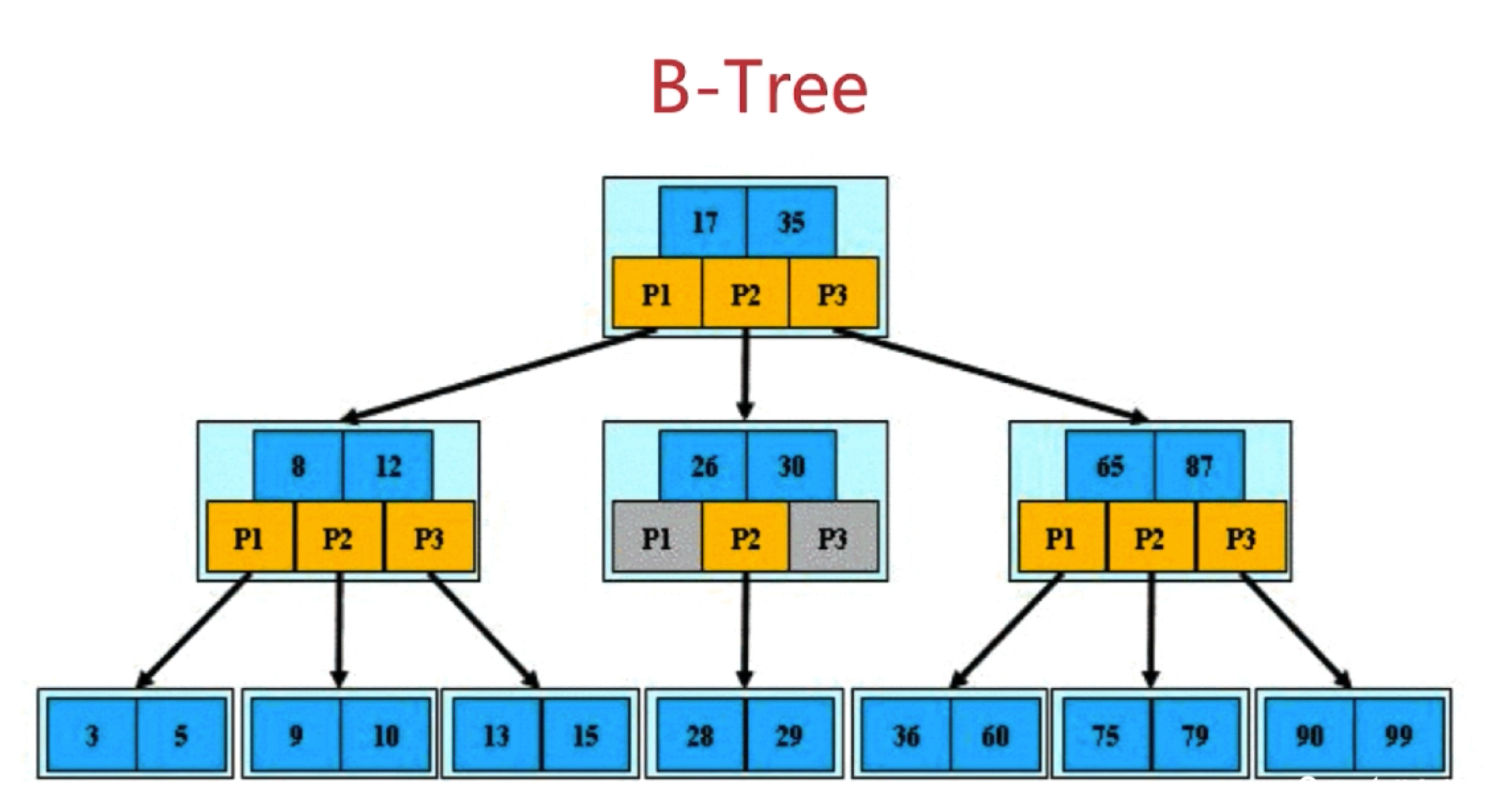
- 根节点至少包括两个孩子
- 树中每个节点最多含有 m 个孩子(m >= 2)
- 除根节点和叶节点外,其他每个节点至少有 ceil(m/2)个孩子
- 所有叶子节点都位于同一层
- 假设每个非终端结点含有n个关键字信息,其中:
- Ki(i=1…n)为关键字,且关键字按顺序升序排列K(i-1) <Ki
- 关键字的个数n必须满足:[ceil(m/2)-1] <= n <= m-1
- 非叶子结点的指针:P[1],P[2],…p[m];其中p[1]指向关键字小于k[1]的子树,p[m]指向关键字大于k[M-1]的子树,其它P[i]指向关键字属于(K[i-1],k[i])的子树。
- 查找效率为O(logn)
3-2-3 优化你的索引-运用B+树
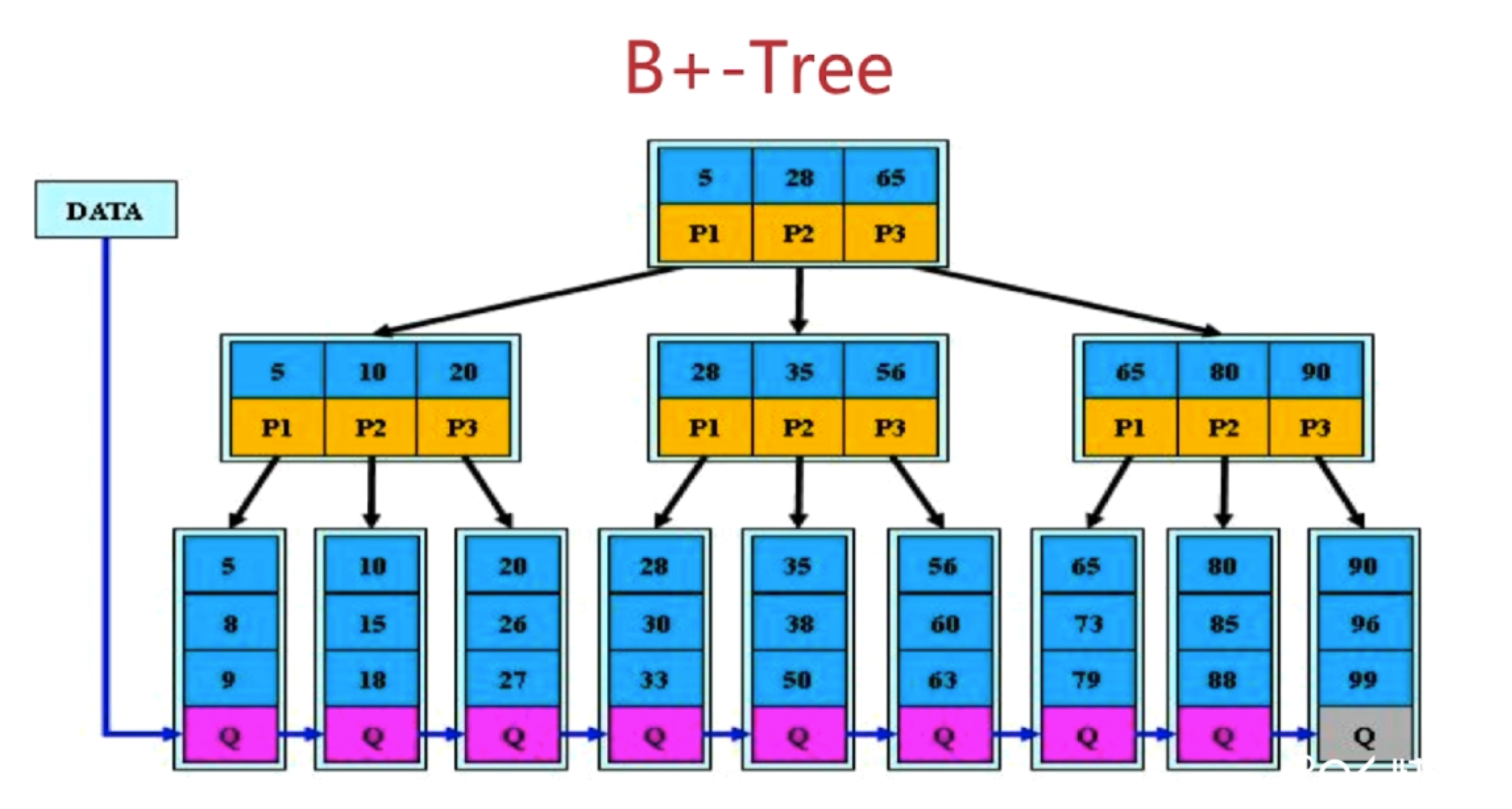
- B+树是 B 树的变体,其定义基本与 B 树相同,除了:
- 非叶子节点的子树指针与关键字个数相同
- 非叶子节点的子树指针 P[i],指向关键字值[K[i],K[i+1])的子树
- 非叶子节点仅用来索引,数据都保存在叶子节点中
- 所有叶子节点均有一个链指向下一个叶子节点
- 结论:B+Tree 更适合用来做存储索引
- B+树的磁盘读写代价更低
- B+树的查询效率更加稳定
- B+树更有利于对数据库的扫描
3-2-4 优化你的索引-运用Hash以及BitMap
Hash 索引
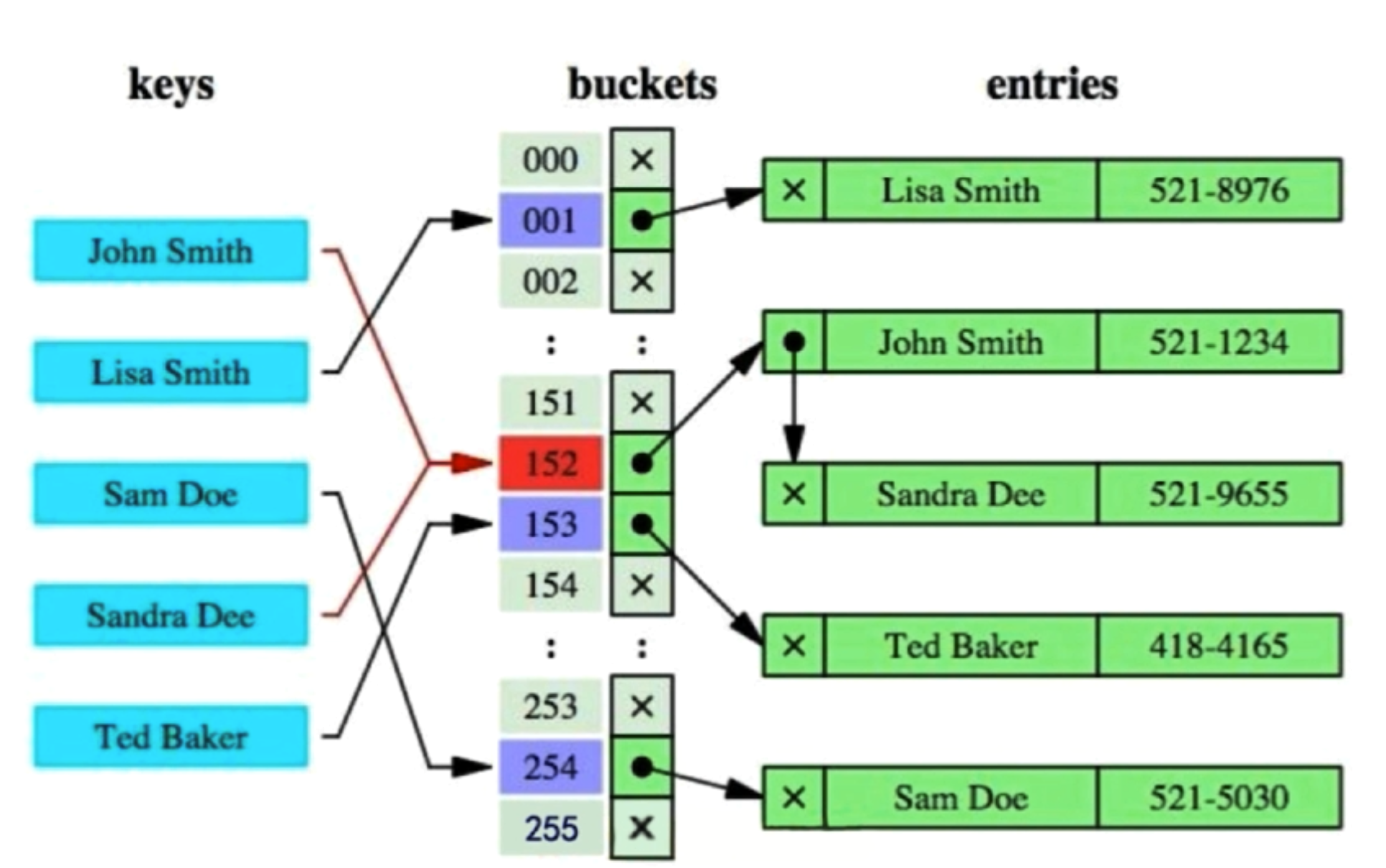
- Hash 索引缺点
- 仅仅能满足“=”,“IN”,不能使用范围查询
- 无法被用来避免数据的排序操作
- 不能利用部分索引键操作
- 不能避免表扫描
- 遇到大量 Hash 值相等的情况后性能并不一定就会比 B-Tree 索引高
BitMap 索引
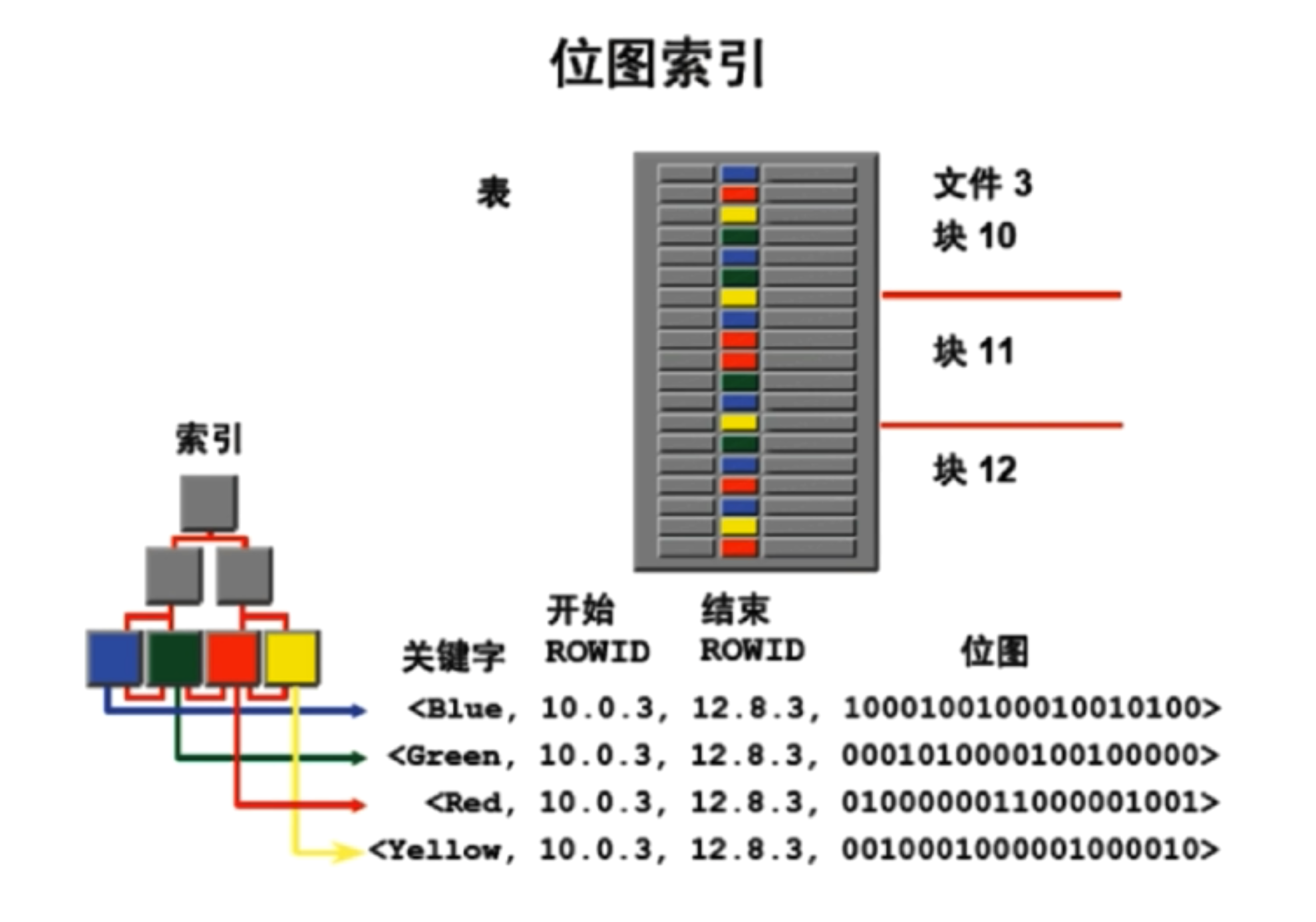
3-2-5 密集索引和稀疏索引的区别
- 密集索引文件中的每个搜索码值都对应一个索引值
- 稀疏索引文件只为索引码的某些值建立索引项
MyISAM
- 不管是主键索引、唯一键索引或者普通索引,其索引都属于稀疏索引
- 索引与数据分开存储
InnoDB
- 若一个主键被定义,该主键则作为密集索引
- 若没有主键被定义,该表的第一个唯一非空索引则作为密集索引
- 若不满足以上条件,InnoDB内部会生成一个隐藏主键(密集索引)
- 非主键索引(稀疏索引)存储相关键位和它对应的主键值,包含两次查找
- 索引与数据存一起
3-2-6 索引额外的问题之如何调优Sql
根据慢日志定位慢查询 Sql
#查询慢日志设置
show variables like '%quer%';
#查询慢日志条数
show status like '%slow_queries%';
#打开慢日志
set global slow_query_log = on;
#设置慢查询阀值,设置完需要重新连接数据库。
set global long_query_time = 1;
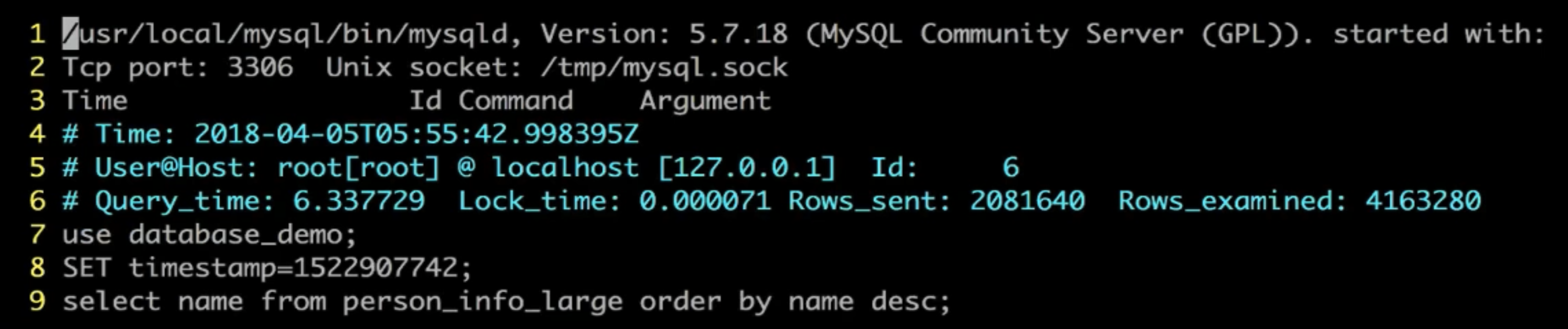
使用 explain 等工具分析 Sql
explain select name from person_info_large order by name desc;
- Explain 关键字段

-
type
Type 类型 解释 system const的特例,仅返回一条数据的时候。 const 查找主键索引,返回的数据至多一条(0或者1条)。 属于精确查找。 eq_ref 查找唯一性索引,返回的数据至多一条。属于精确查找。 ref 查找非唯一性索引,返回匹配某一条件的多条数据。属于精确查找、数据返回可能是多条。 range 查找某个索引的部分索引,一般在where子句中使用 < 、>、in、between等关键词。只检索给定范围的行,属于范围查找。 index 查找所有的索引树,比ALL要快的多,因为索引文件要比数据文件小的多。 ALL 不使用任何索引,进行全表扫描,性能最差。 -
extra
- extra 中出现以下2项意味着 MySQL 根本不能使用索引,效率会受到重大影响。应尽可能对此进行优化
extra 项 说明 Using FileSort 说明MySQL会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取,即MySQL无法使用索引完成的排序称为"文件排序"。 Using temporary MySQL在对查询结果进行排序的时候使用了临时表,常见于排序OrderBy 和分组查询GroupBy。
-
修改 Sql 或者尽量让 Sql 走索引
- 修改 Sql
- 给查询项加索引
alter table person_info_large add index idx_ name(name);
3-2-7 索引额外问题之最左匹配原则的成因
- 什么是最左匹配原则
- MySQL会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如 a =3 and b = 4 and c > 5 and d = 6;如果建立(a,b,c,d)顺序的索引,d 是用不到索引的,如果建立(a,b,c,d)的索引则都可以用到,a,b,d 的顺序可以任意调整。
- = 和 in 可以乱序,比如 a = 1 and b = 2 and c = 3;建立(a,b,c)索引可以任意顺序,MySQL 的查询优化器会帮助你优化成索引可以识别的形式。
- 联合索引的最左匹配原则的成因
- 联合索引的最左原则就是建立索引KEY union_index (a,b,c)时,等于建立了(a)、(a,b)、(a,b,c)三个索引,从形式上看就是索引向左侧聚集,所以叫做最左原则,因此最常用的条件应该放到联合索引的组左侧。
- MySQL创建复合索引的规则是首先会对复合索引的最左边,也就是索引中的第一个字段进行排序,在第一个字段排序的基础上,在对索引上第二个字段进行排序,其实就像是实现类似order by 字段1,字段2这样的排序规则,那么第一个字段是绝对有序的,而第二个字段就是无序的了,因此一般情况下直接只用第二个字段判断是用不到索引的。
3-2-8 索引额外问题之索引是建立越多越好吗
- 答案是否定的
- 数据量小的表不需要建立索引,建立会增加额外的索引开销
- 数据变更需要维护索引,意味着更多的索引意味着更多的维护成本
- 更多的索引也需要跟多的存储空间
3-3 锁模块
- 数据库锁的分类
- 按锁的粒度划分,可分为表级锁,行级锁,页级锁
- 按锁的级别划分,可分为,共享锁,排它锁
- 按加锁方式划分 ,可分为,显示锁,自动锁
- 按操作划分,可分为,DML锁,DDL锁
- 使用方式来划分,可分为,乐观锁,和悲观锁
3-3-1 锁模块之MyISAM与InooDB关于锁方面的区别
- 共享锁(S锁)又称读锁,若事务T对数据对象A加上S锁,则事务T可以读A但不能修改A,其他事务只能再对A加S锁,而不能加X锁,直到T释放A上的S 锁。这保证了其他事务可以读A,但在T释放A上的S锁之前不能对A做任何修改。
- 排他锁(X锁)又称写锁。若事务T对数据对象A加上X锁,事务T可以读A也可以修改A,其他事务不能再对A加任何锁,直到T释放A上的锁。这保证了其他事务在T释放A上的锁之前不能再读取和修改A。
X S X 冲突 冲突 S 冲突 兼容
-
手动加(解)读\写锁
lock tables 表名 read; lock tables 表名 write; unlock tables; -
MyISAM默认用的是表级锁,不支持行级锁
-
InnoDB 默认用的是行级锁,也支持表级锁
-
MyISAM 适合的场景
- 频繁执行全表 count 语句
- 对数据进行增删改的频率不高,查询非常频繁
- 没有事物
-
InnoDB 适合的场景
- 数据增删改查都相当频繁
- 可靠性要求比较高,要求支持事物
3-3-2 锁模块之数据库事务的四大特性
- ACID
- 原子性 (Atomic)
- 一致性 (Consistency)
- 隔离性 (Isolation)
- 持久性 (Durability)
3-3-3 锁模块之事务并发访问产生的问题以及事务隔离机制
- 更新丢失 —— MySQL 所有事物隔离级别在数据库层面上均可避免
- 脏读 —— READ-COMMITTED 事物隔离级别以上可避免
- 不可重复读 —— REPEATABLE-READ 事务隔离级别以上可避免
- 幻读 —— SERIALIZABLE事务隔离级别可避免
| 事物隔离级别 | 更新丢失 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|---|
| 未提交读 | 避免 | 发生 | 发生 | 发生 |
| 已提交读 | 避免 | 避免 | 发生 | 发生 |
| 可重复读 | 避免 | 避免 | 避免 | 发生 |
| 串行化 | 避免 | 避免 | 避免 | 避免 |
3-3-4 锁模块之当前读和快照读
-
当前读和快照读
- 当前读:select...lock in share mode;select...for update;
- 当前读:update,delete,insert
- 快照读:不加锁的非阻塞读,select
-
RC、RR 级别下的 InnoDB 的非阻塞读如何实现
- 数据行里的DB_TRX_ID、DB_ROLL_PTR、DB_ROW_ID 字段
- undo 日志
- read view
3-3-5 锁模块之RR如何避免幻读
- 表象:快照读(非阻塞读)——伪 MVCC
- 内在:next-key 锁(行锁+gap 锁)
- 行锁
- Gap 锁
- 如果where 条件全部命中,则不会加Gap锁,只会加记录锁
- 如果where条件部分命中,或者全部命中,则会加上Gap锁。
3-4 关键语法讲解
- GROUP BY
- 满足“SELECT 子句中的列名必须为分组列或列函数”
- 列函数对于GROUP BY子句定义的每个组各返回一个结果
- HAVING
- 通常与GROUP BY子句一起使用
- WHERE 过滤行,HAVING 过滤组
- 出现在同一SQL 的顺序:WHERE>GROUP BY>HAVING
- 统计相关:COUNT,SUN,MAX,MIN,AVG