10-1 Java异常体系
-
异常处理机制主要回答了三个问题
- What:异常类型回答了什么被抛出
- Where:异常堆栈跟踪回答了在哪抛出
- Why:异常信息回答了为什么被抛出
-
Error和Exception的区别?

- Error:程序无法处理的系统错误,编译器不做检查
- Exception:程序可以处理的异常,捕获后可能回复
- 总结:前者时程序无法处理的错误,后者是可以处理的异常
- 从责任角度看:
- Error属于JVM需要负担的责任
- RuntimeException是程序应该负担的责任
- CheckedException可检查异常是java编译器应该负担的责任
-
常见异常
- RuntimeException:不可预知的,程序应当自行避免(比如加入if(name!=null))
- NullPointerException - 空指针引用异常
- ClassCastException - 类型强制转换异常
- IllegalArgumentException - 传递非法参数异常
- IndexOutOfBoundsException - 下标越界异常
- NumberFormatException - 数字格式异常
- 非RuntimeException:可预知的,从编译器校验的异常
- ClassNotFoundException 找不到指定class的异常
- IOexception IO操作异常
- FileNotFoundException 找不到指定文件的异常
- Error常见的异常:
- NoClassDefFoundError 找不到class定义的异常
- class或jar不存在
- 类文件存在但是在不同的域中
- 大小写问题,javac无视大小写
- StackOverflowError 深递归导致栈被消耗尽而抛出的异常
- OutOfMemoryError 内存溢出异常
- NoClassDefFoundError 找不到class定义的异常
- RuntimeException:不可预知的,程序应当自行避免(比如加入if(name!=null))
10-2 Java异常要点分析
-
Java 的异常处理机制
- 抛出异常:创建异常对象,交由运行时系统处理
- 捕获异常:寻找合适的异常处理器处理异常,否则终止运行
-
Java 异常的处理原则
- 具体明确:抛出的异常应能通过异常类名和 message 准确说明异常的类型和产生异常的原因;
- 提早抛出:应尽可能早的发现并抛出异常,便于精确定位问题;
- 延迟捕获:异常的捕获和处理应尽可能延迟,让掌握更多信息的作用域来处理异常。
-
高效合理的异常处理框架
在用户看来,应用系统发生的所有异常都是应用系统内部的异常- 设计一个通用的继承自RunntimeException 异常来统一处理
- 其余异常都统一转译为上述异常 AppException
- 在 catch 之后,抛出上述异常的子类,并提供足以定位的信息
- 由前端接收 AppException 做统一处理
-
Java 异常处理消耗性能的地方
- try-catch 块影响 JVM 的优化
- 异常对象实例需要保存栈快照等信息,开销较大
10-3 Collection体系
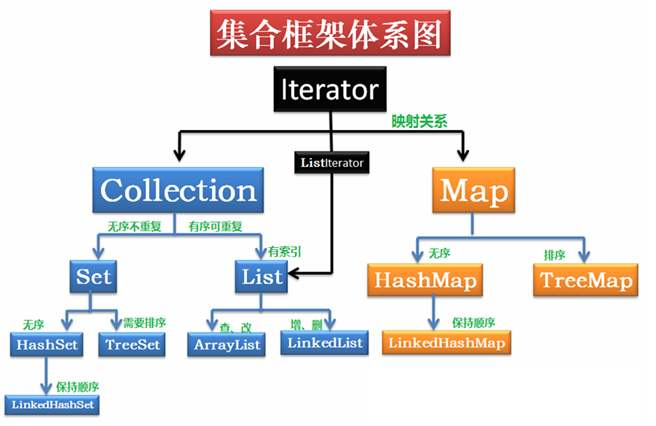
- 集合之 List 和 Set

10-4 HashMap

-
HashMap(JDK8以前):数组+链表;(JDK8以后):数组+链表+红黑树
-
put 方法的逻辑
- 如果 HashMap 未被初始化过,则初始化
- 对 Key 求 Hash 值,然后再计算下标
- 如果没有碰撞,直接放入桶中
- 如果碰撞了,以链表的方式链接到后面
- 如果链表长度超过阀值,就把链表转成红黑树
- 如果链表长度低于6,就把红黑树转回链表
- 如果节点已经存在就替换旧值
- 如果桶满了(容量16*加载因子0.75),就需要 resize(扩容两倍后重排)
-
HashMap;如何有效减少碰撞
- 扰动函数:促使元素位置分布均匀,减少碰撞几率
- 使用 final 对象,并且采用合适的 equals() 和hashCode() 方法(String、Interger)
- HashMap从获取 hash 到散列的过程
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }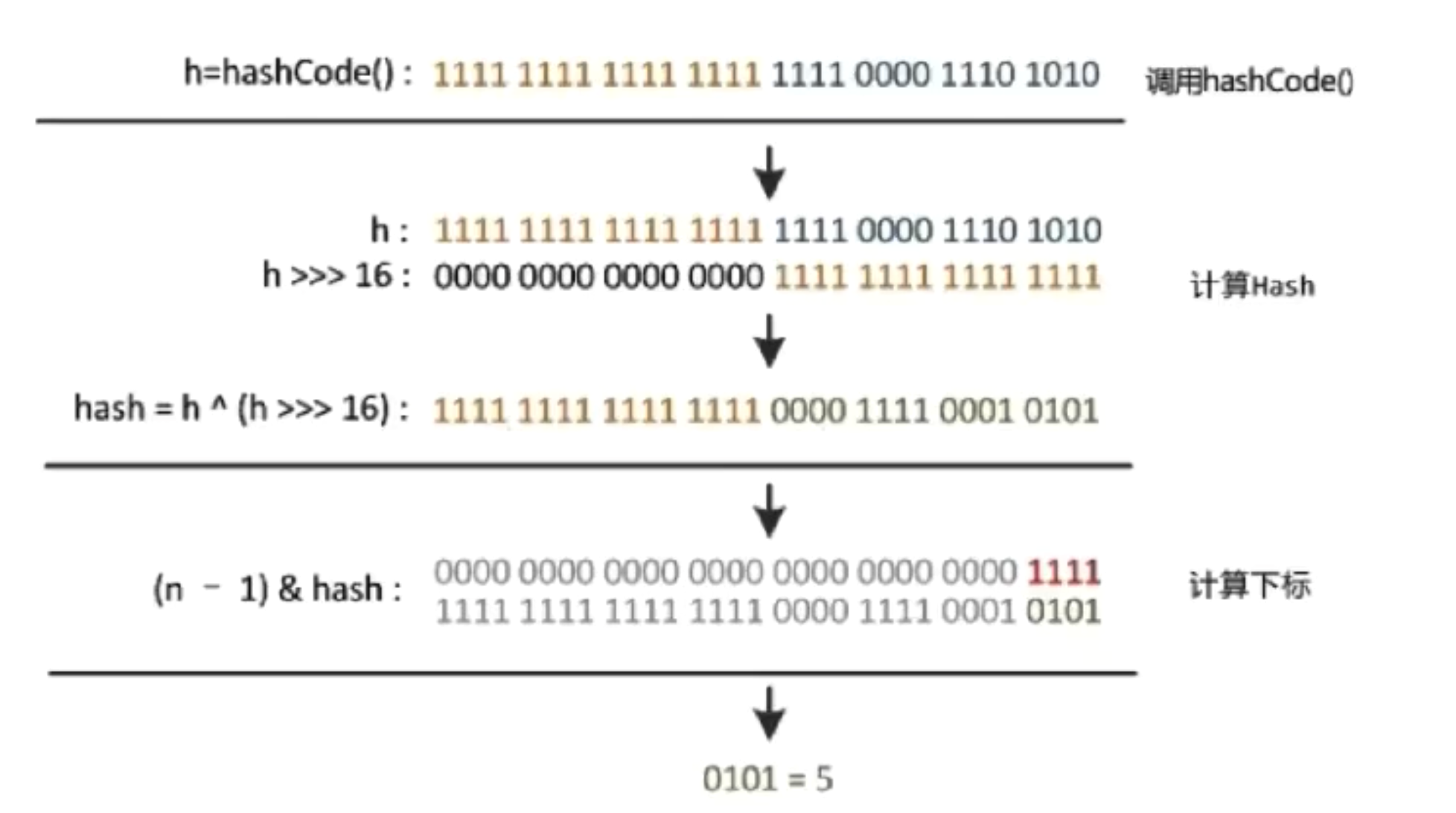
-
HashMap:扩容的问题
- 多线程环境下,调整大小会存在条件竞争,容易造成死锁
- rehashing 是一个比较好事的过程
10-5 ConcurrentHashMap
-
如何优化 Hashtable
- 通过锁细粒度化,将整锁拆解成多个锁进行优化
-
ConcurrentHashMap:CAS+synchronized 使锁更细化
-
put 方法的逻辑
- 判断 Node[] 数组是否初始化,没有则进行初始化操作
- 通过 hash 定位数组的索引坐标,是否有 Node 节点,如果没有则使用 CAS 进行添加(链表的头结点),添加失败则进入下次循环。
- 检查到内部正在扩容,就帮助它一块扩容
- 如果 f!=null,则使用 synchronized 锁住 f 元素(链表/红黑二叉树的头元素)
- 如果使 Node(链表结构),则执行链表的添加操作
- 如果使 TreeNode(树形结构),则执行树添加操作
- 判断链表长度已经达到临界值8,当节点数超过这个值就需要吧链表转换为树结构
-
HashMap、Hashtable、ConccurentHashMap 三者的区别:
- HashMap 线程不安全,数组+链表+红黑树
- Hashtable 线程安全,锁住整个对象,数组加链表
- ConccurentHashMap 线程安全,CAS+同步锁,数组+链表+红黑树
- HashMap 的 key、value 均可为 null,而其他两个类不支持
10-6 J.U.C包的梳理
- java.util.concurrent:提供了并发编程的解决方案
- CAS 是 java.util.concurrent.atomic 包的基础
- AQS 是 java.util.concurrent.locks 包以及一些常用类比如 Semophore、ReentrantLock 等类的基础
- J.U.C 包的分类
- 线程执行器 executor
- 锁 locks
- 原子变量类 aotmic
- 并发工具类 tools
- 并发集合 collections
- 并发工具类
- 闭锁 CountDownLatch
- 栅栏 CyclicBarrier
- 信号量Semaphore
- 交换器 Exchanger
10-7 Java的IO机制
-
Block-IO:InputStream 和 OutputStream,Reader 和 Writer

- BIO 特点:IO 执行的两个阶段都被阻塞了
- BIO 好处:代码简单、直观
- BIO 缺点:IO 的效率和扩展性存在瓶颈
-
NonBlock-IO:构建多路复用的、同步非阻塞的 IO 操作
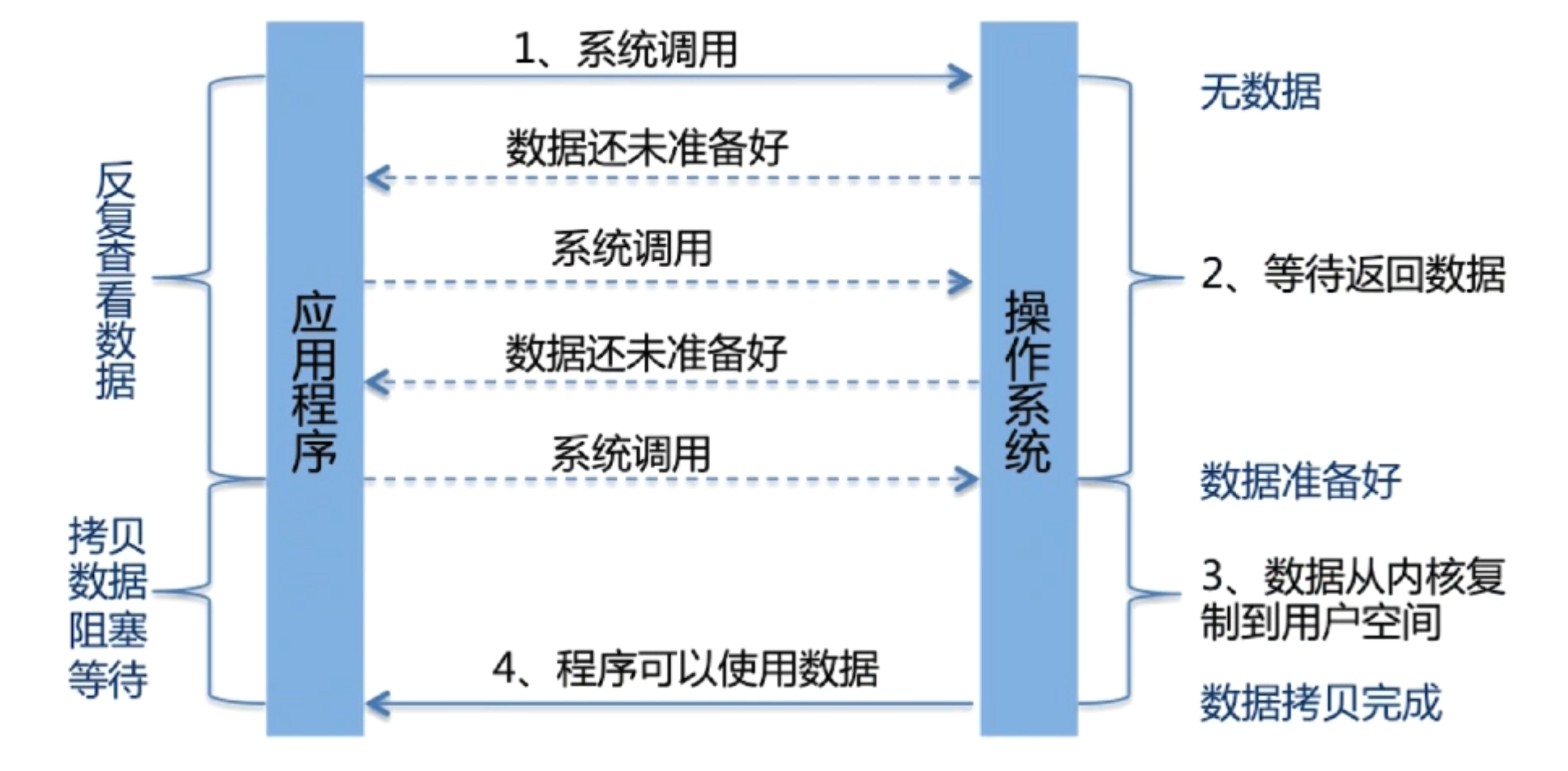
- NIO 核心
- Channels(网络文件传输、大数据传输)
- FileChannel
- DatagramChannel
- SocketChannel
- ServerSocketChannel
- Buffers
- ByteBuffer
- CharBuffer
- DoubleBuffer
- FloatBuffer
- IntBuffer
- LongBuffer
- ShortBuffer
- MappedBytrBuffer
- Selectors
- Channels(网络文件传输、大数据传输)
- NIO 核心
-
IO多路复用:调用系统级别的 select\poll\epoll

-
select、poll、epoll 的区别
支持一个进程所能打开的最大连接数 FD 剧增后带来的 IO 效率问题 消息传递方式 select 单个进程所能打开的最大连接数由 FD_SETIZE宏定义,其大小使32个整数的大小(在32位的机器上,大小使3232,64位的机器上为3264),我们可以对其进行修改,然后重新编译内核,但是性能无法保证,需要做进一步测试 因为每次调用时都会对连接进行线性遍历,所以随着 FD 的增加会造成遍历速度的“线性下降”的性能问题 内核需要将消息传递到用户空间,需要内核的拷贝动作 poll 本质上和 select 没有区别,但是它没有最大连接数的限制,原因使它是基于链表来存储的 同上 同上 epoll 虽然连接数有上限,但是很大,1G 内存的机器上可以打开10万左右的连接 由于 epoll 是更具每个 fd 上的 callback 函数来实现的,只有活跃的 socket 才会主动调用 callback,所以在活跃 socket 较少的情况下,使用epoll 不会有“线性下降”的性能问题,但是所有 socket都很活跃的情况下,可能会游性能问题 通过内核和用户空间共享一块内存来实现,性能较高
-
-
Asynchronous IO:基于事件和回调机制

- AIO 如何进一步加工处理结果
- 基于回调:实现 CompletionHandler 接口,调用时触发回调函数
- 返回 Future:通过 isDone() 查看是否准备好,通过 get() 等待返回数据
- AIO 如何进一步加工处理结果
-
BIO、NIO、AIO 对比
属性\模型 阻塞 BIO 非阻塞 NIO 异步 AIO blocking 阻塞并同步 非阻塞但同步 非阻塞并同步 线程数(Server:Client) 1:1 1:N 0:N 复杂度 简单 较复杂 复杂 吞吐量 低 高 高